






2026 Digital Marketing Predictions — What’s Next & What It Means for Your Strategy
SEO
One of the key goals of technical SEO is to make your website more visible. And the first step to visibility is Google finding and understanding your site. If Google doesn’t understand your site, it’s not likely to rank it highly in the SERPs. Crawling – where Google bots find and explore your site – is a big component of this.
Crawling is when bots (spiders) search your site’s individual pages to determine their value. As the bots do this, they collect data, which search engines like Google and Bing use to match search queries with relevant results.
Without crawling, your content won’t be viewable anywhere on the search engine, and users won’t be able to find your website.
Bots are able to do a lot of things, but have limits. These key terms will help explain a bot’s role:
That said, crawls can be limited by the functionality of websites. Crawl anomalies can be caused by issues such as blocked CSS and JavaScript resources, infinite crawl spaces, and session identifiers, all of which can cause issues during the crawling process.
First, bots visit a list of known indexed URLs, or through the sitemap submitted by the website owner.
The bots then “fetch” the HTML of each page it visits – like what a browser does when you visit a website – and reads it, follows links present (internal and external) to discover new pages. The process continues, creating a network of discovered pages.
The information from each page is recorded in the search engine’s index, which contains hundreds of billions of web pages reaching a data size of over 100 million gigabytes. Crawlers regularly revisit sites to check for updates and new content, to keep its index up to date.
Crawling can range from a few hours to several weeks, depending on a few factors such as:
So, like many other aspects of SEO, the answer is, “it depends”.
Crawling is a cornerstone of SEO because it’s constantly in motion, updating the search engine with new data and pages, which it leverages for user experience.
By having a website hierarchy that puts your most important pages (usually your money pages) higher up, so they are crawled first and more often, it means Google is more likely to rank those.
If you have service pages way down in the hierarchy, they will be seen by the bots – and therefore Google – as less important. Likewise, if you have too many pages high up in the hierarchy, Google can split the importance across those pages, meaning each page is seen as less important.
Also, the bots could identify errors in your website’s infrastructure such as bad link structures, irrelevant content, and functional issues such as broken links.
This can be helpful for your SEO agency, as it flags up issues that might have gone unnoticed and helps improve the overall user experience.
To stay ahead of the curve, make crawling a priority in your SEO strategy.
While Google will automatically crawl your site if it’s indexed, you can speed up the process.
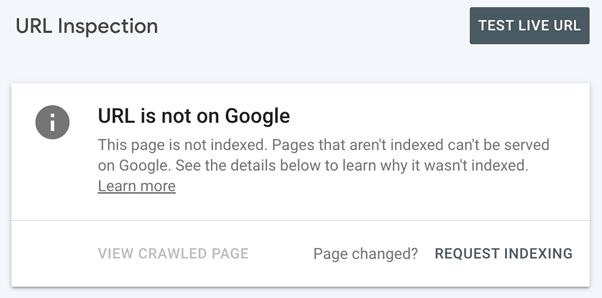
The quickest way to get your website crawled is through Google Search Console. Sign up and then go to the URL inspection tool and request indexing for your root domain.
This is what an unindexed page looks like there. Select “Request Indexing”.
Now Googlebot visits your website and scans the content, following links to the new pages and gathering all the information present, processing and storing it in Google’s index. Because of this, search engines can quickly retrieve data for users.
An XML Sitemap tells crawlers how to navigate your site, helping crawlers to understand its structure and to prioritise important pages. We highly recommend you do this for efficient crawling.
You can add it by selecting “Add a new sitemap” and following the instructions as presented here:
By regularly creating fresh, valuable content, you encourage frequent crawling. For instance, an internal linking structure allows crawlers to discover your new content fast. Backlinks are good too, as they signal your site’s value to Google.
Other actions to consider:
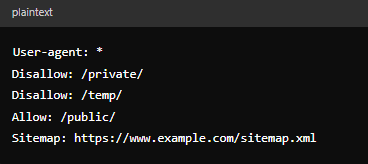
A robots.txt file instructs bots on which pages to crawl and which to avoid, thereby managing crawler traffic by preventing the overloading of a website.
If bots visit your site and finds no robots.txt file, it will crawl the entire site. This is ok for small sites, but if you’re a site with thousands – or possibly millions – of pages, it can become an issue.
Here is an example of robots.txt code, with each component explained:
Google uses mobile-first indexing, so ensure your site is mobile friendly.
HTTPS encrypts data between the user’s browser and your server, ensuring your site is secure. HTTPS is one of Google’s ranking factors and so could improve your visibility.
There are several ways to check on your site’s crawl status:
Google Search Console provides detailed reports on crawling activity, including how many requests Googlebot has made to your site over the last 90 days.
Check your server logs for bot entries. Look at the user agents, for Google they are called “Googlebot”. If you find files mentioning the bot, then your site is being crawled.
Test your robots.txt file in Google Search Console or Bing Webmaster Tools to ensure it’s not blocking important pages from being crawled.
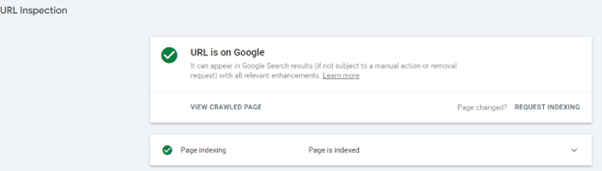
The URL Inspection Tool allows you to check the crawl status of specific URLs. It informs you when the URL was last crawled, and any issues encountered.
If your pages appear in the search engine results page (SERPs), then your website has been crawled and indexed.
Use the “Pages” report in GSC, which reports back on what they have crawled and provides an indexed status so you can see what is and isn’t indexed and why.
Crawl budget is the capacity a search engine has for crawling your site. The more efficient your website, the greater your crawl budget. Consequently, your site gets ranked faster.
Crawling takes time and energy through data transfer and processing. For each page request (crawl), the server sends an HTTP request.
Images scripts and CSS files all must be loaded. Crawlers must extract relevant information from the various code formats (HTML, CSS and JavaScript) included in your site.
It takes roughly:
The more requests the crawlers must make, the higher the strain on your website. Websites with high traffic levels, for instance, need efficient servers to handle the load.
There are several ways to make your website quicker for search engines to crawling, and spend your crawl budget more efficiently:
Remember, you can hire a digital marketing agency to do all of this for you.
Google’s crawl frequency depends on the website. High-traffic news sites like the BBC, for example, will be crawled multiple times a day because they are constantly updating their content with breaking news. Google crawls them often to ensure the latest news is available in search results.
E-commerce sites have moderate traffic and are crawled a few times a week, and low-traffic sites like personal blogs are crawled weekly or sometimes bi-weekly.
For websites just launched, migrations, and rebranded sites, the crawl frequency will be more frequent initially, and then stabilise. Google prioritises crawling new or significantly modified sites.
Crawling is a fundamental part of SEO that drives business and helps users. Optimising your website for efficient crawling improves indexing, maximises your crawl budget, and gets you higher in the SERPs. It also detects errors, putting them on your radar earlier than otherwise. All of these efforts combined positively impact user experience and your website.
Develop a crawl strategy and you can reap all these benefits. Contact us to learn how we can help you get there.


